The book has been written by Sam Newman, who talks about microservice architecture usage around the world, including in organizations like Netflix, Amazon, Gilt and the REA group, who have all found that the increased autonomy gives huge advantages to their teams. While I was reading this book, I got the similar feelings to the books such as “Clean Code” and “Clean Architecture”. The author has collected many useful experiences about microservice architecture, some of them very familiar to us, but some of them are gives us “aha” points.

What Makes a Good Service?
The author emphasizes the terms most of us heard many times “Loose Coupling” and “High Cohesion”. Me personally heard this terms since very very beginning of my programming career (which goes back to B.C). But one going to understand the real meaning of these words after long sufferings.
Loose Coupling
When services are loosely coupled, a change to one service should not require a change to another service. The main purpose of introducing MSA is exactly about making the system loosely coupled. Where the developer must be able to make a change to one service and deploy it, without needing to change any other part of the system. The author describes details of the loosely coupling problem in Chapter 4(Integration) with good examples and ways.
High Cohesion
All the related behaviors must sit together, and unrelated behaviors to sit elswhere. When new changes to the behavior should be applied then we should able to change in one place and deploy. Making changes in lots of different places is slower and error prone. It also may cause the safe deployment problems. Because changed behaviors must be deployed togethere at once, otherwise it may cause a big chaose of inconsistency.
Technical Dept
If we need to make a choice to cut a few corners to get some urgent features out, then it creates a technical dept, It might have a short-term benefit but a long-term cost. Technical dept must be considered just like dept in the real world. It has an ongoing cost, and is something we want to pay down.
Postel’s Law
Be conservative in what you do, be liberal in what you accept from others
Postel’s Law
Originally the concept of this law was intended to the interaction of devices over networks, where you should expect all sorts of odd things to happen.
The Cascade
Cascading failures can be especially dangerous in a situation where the network connection between the services goes down. The services themselves appear to be healthy, but they can’t talk to each other for some reason. That means looking into the health of each services would not reveal the whole problem. Worst scenario could happen when the network is not eliminated at all but just behaves unreliably (means it gets really slow, or some packets are passed some not). Synthethical mimicing the whole flow of the processes could reveal the problem in this case. But synthetical mimicing cannot be easily performed or deployed in a real production environment.
Therefore, monitoring the integration points between systems becomes a key. Each service instance should track and expose the health of its downstream dependencies, from the database to other collaborating services. Response time should be also measured for the downstream calls, and also detect if it is erroring.
Releases and Versioning
Canary Release
Canary release happens when we are verifying our newly deployed software by directing amounts of production traffic against the system to see if it performs as expected. Canary release can cover a number of things, both functional (how the api responds) and non-functional(api response latency). It also gives us chance to compare with current and previous release comparison. After canary release usually the heavy monitoring of that server happens. If some unexpected results and malfunctionings are detected then quick roll-back can be applied.
Semantic Versioning
Semantic Versioning is a specification that allows give a version number to API. With semantic versioning, each version number is represented in a form: MAJOR.MINOR.PATCH. Where MAJOR number increments when backward incompatible changes are applied to the API. MINOR increments when the new functionality is added, but no existing functionality has been removed. That means incremented MINOR version can be compatible with previous versions. PATCH incrementing usually means bug fixes without updating any upstream and downstream interfaces.
Coexist Different Endpoints
If the breaking change in the new API must be released, then we deploy a new version of the service that exposes both the old and new versions of the endpoint. This will open up new endpoint of the API as soon as possible, along with the old API interface.
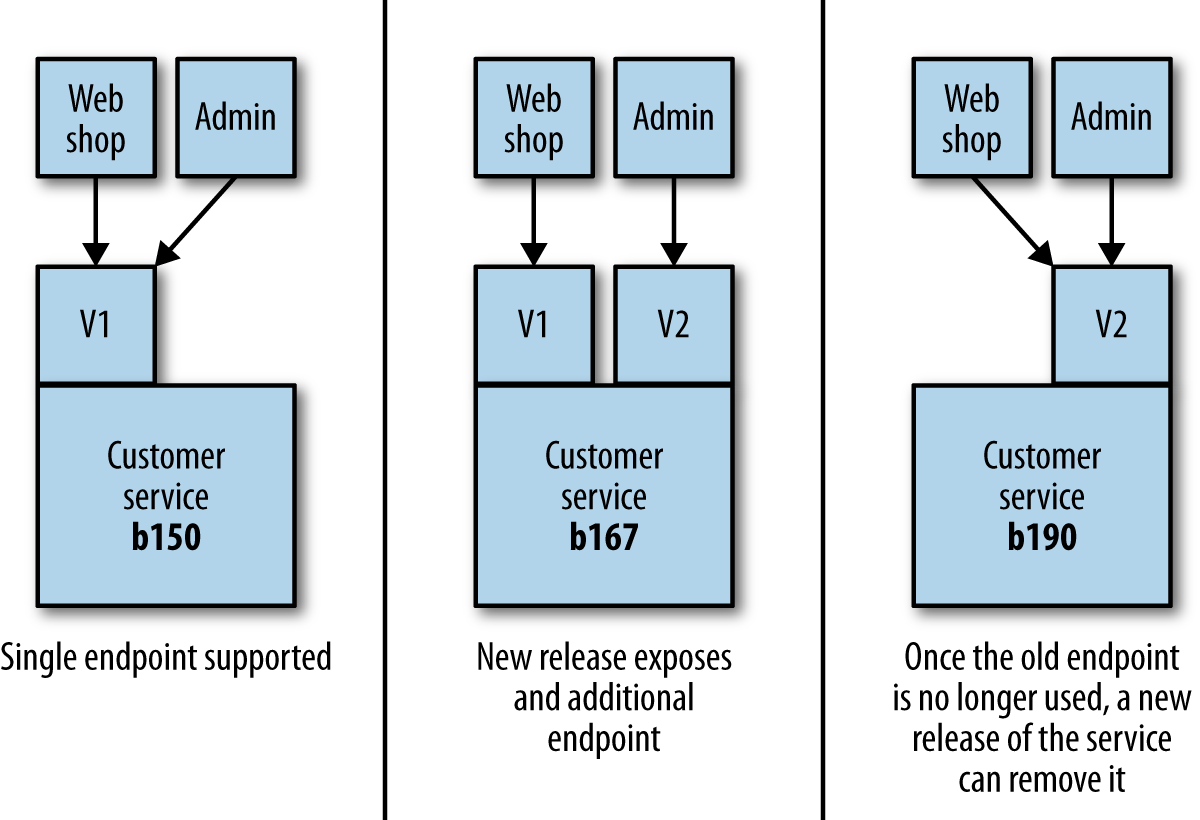
After release all the depedant services are informed about deprectation of the old API, and suggested them to switch new one. When everyone who consumes the old API interface switched to new one, then the old API must be terminated. Old API must be monitored for some time to not holding any incoming request, if incoming requests are appeared then turning-off the interface may harm the system. When all dependent services are switched to new V2 version of the API then V1 can be completely removed (as depicted in figure above).
Catastrophic Failover
Author refers to Martin Fowler’s Catastrophic Failover problem with his own past experience. It is worth to read and learn from.
A bug had crept in whereby a certain type of pricing request would cause a worker to crash. We were using a transacted queue: as the worker died, its lock on the request timed out, and the pricing request was put back on the queue - only for another worker to pick it up and die. This was a classic example of what Martin Fowler calls a catastrophic failover
Sam Newman