Parquet format is quite popular and well-used among big-data engineers, and most of the case they have setup to read and check the content of parquet files. But sometimes we may need to quickly check the content of parquet. There are many ways and tools to do that, but I would like to talk about the way to do that using S3 Select feature. Most people who has taken any aws course most probably heard about it, but it passes quickly and unnoticably to our ears. It is quite powerful quick tool to know.
Quick Overview on S3 Select and Glacier Select
S3 Select is a great feature when you quickly need to query your data stored on S3. Without spending any time to ramp-up the cluster that could do the same job. Lets see the quick definitions of these features:
- S3 Select: uses SQL statements to filter out the contents of S3 objects and retrieve just the subset of required data
- Glacier Select: uses SQL statements directly on data in S3 Glacier without having to restore data to a more frequently accessible tier
Below we can see quick aws services comparison table:
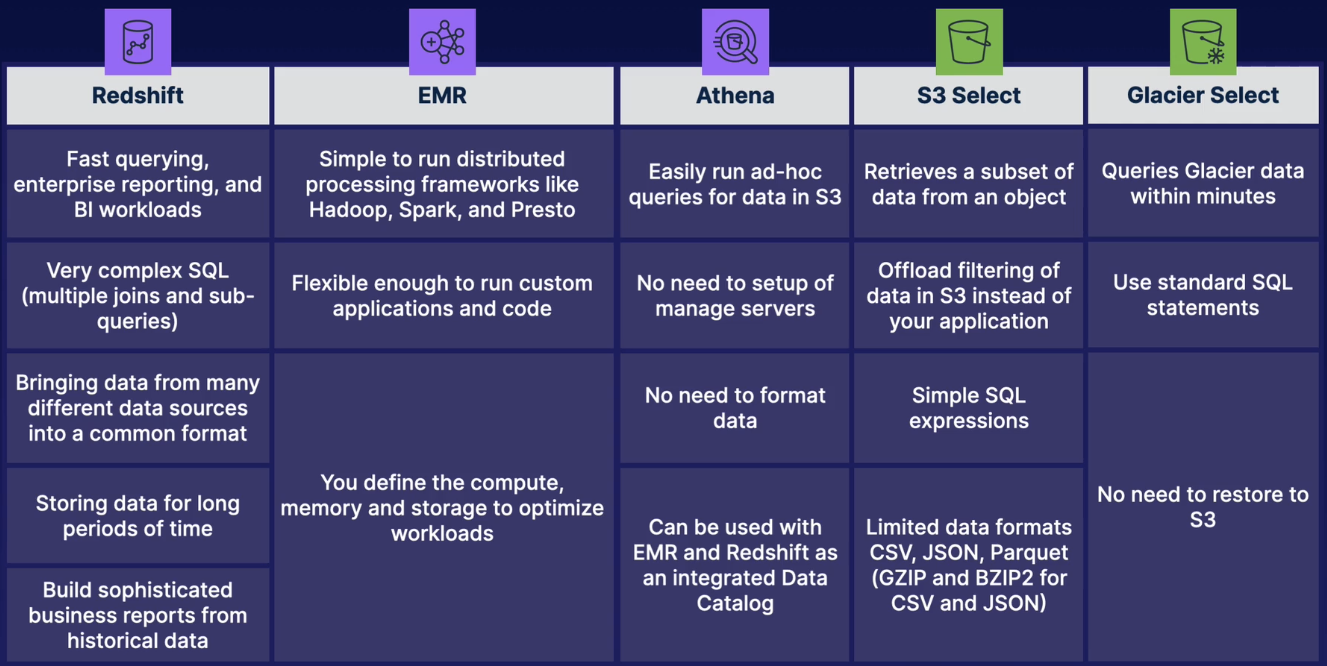
Important to remember S3 Select is used when query is performed on single S3 object. It can return just a few bytes in a large object. Another advantage is that query runs on S3 itself rather than on your application. If the query need to be run over all S3 bucket objects then we should consider other services (Athena could be a good candidate)
Query Parquet file in S3
Below is a quick python lambda-example that does select inside the S3, parquet format:
import json
import boto3
s3 = boto3.client('s3')
def lambda_handler(event, context):
# define bucket and object-key
bucket = event['bucket']
key = event['key']
# just putting some limit for a querying
limit = 10
if ('limit' in event):
limit = event['limit']
r = s3.select_object_content(
Bucket=bucket,
Key=key,
ExpressionType='SQL',
Expression="select * from s3object limit " + str(limit),
InputSerialization={'Parquet': {}},
OutputSerialization = {'CSV': {}},
)
lines = []
# iterate through a results
for event in r['Payload']:
if 'Records' in event:
records = event['Records']['Payload'].decode('utf-8')
lines.append( records)
print(records)
elif 'Stats' in event:
statsDetails = event['Stats']['Details']
print("Stats details bytesScanned: ")
return {
'statusCode': 200,
'body': lines
}
In order to run this lambda you can give following test input json object:
{
"bucket": "rustams-bucket-or-any-bucket-you-want",
"key": "here/you/can/define/path/to/parquetobject/part-00000-e04839d0-c611-4613-b4e7-aa8ae7a4cba3-c000.snappy.parquet"
}
Conclusion
As we can see it is quick tool to look into a single S3 object content and perform SQL query inside. We can easily extend this application that could scan through a S3 bucket and perform queries individually in each object. But then we have to build a some kind of reduce model to collect all responses into one. That is why when it is needed to query over a bucket Athena is a more preferred service.