- Kafka allows us to decouple data-streams and applications
-
Created by Linkedln, now Open Source project and maintainted by Confluent
- Horizontal scalability:
- Can scale to 100s of brokers
- Can scale to millions of messages per second
- High performance (latency of less than 10ms) - real time
- Used by the 2000+ firms
Apache Kafka: Use cases
- Messaging System
- Activity Tracking
- Gather metrics from many different locations
- Application Logs gathering
- Stream processing (with the Kafka Streams API or Spark for example)
- De-coupling of system dependencies
- Integration with Spark, Flink, Storm, Hadoop and many other Big Data technologies
How the Kafka used in Companies:
- Netflix uses Kafka to apply recommendations in real-time while user watches TV shows
- Uber uses Kafka to gather user, taxi and trip data in a real-time to compute and forecast demand, and compute surge pricing in real-time
- Linkedln uses Kafka to prevent spam, collect user interactions to make better connection recommendations in real time
Topics, partitions and offsets
- Topics: a particular stream of data
- Similar to a table in a database (without all the constraints)
- You can have as many topics as you want
- Topic is identified by its name
- Topics are split in partitions
- Each partition is ordered
- Order is guaranteed only within a partition(not across partitions)
- Each message within a partition gets an incremental offset
- When topic is created the number partitions must be defined
- When topic is created a replication factor should be choosen (usually bigger than 1)
- Data within partition kept only for a limited time (default is one week)
- Data inside partition is immutable, means once data is written to a partition, it can’t be changed
- Data is assigned randomly to a partition unless a key is provided
Brokers
Brokers hold the topics (distributed among multiple brokers), and Kafka cluster is a composed of multiple brokers (servers)
- Each broker is identified with its ID (integer <- must be a number)
- Connection to any broker (called a bootstrap broker) means you are connected to the entire cluster
- A good number to get started is 3 brokers, but some big clusters have over 100 brokers
Concept of Leader for a Partition
- At any time only ONE broker can be a leader for a given partition
- Only that leader can receive and serve data for a partition
- The other brokers will syncrhonize the data
- Each partition has one leader and multiple ISR (in-sync replica)
Producers
- Producers write data to topics
- Producers automatically know to which broker and partition to write to
- In case of Broker failures, Producers will automatically recover
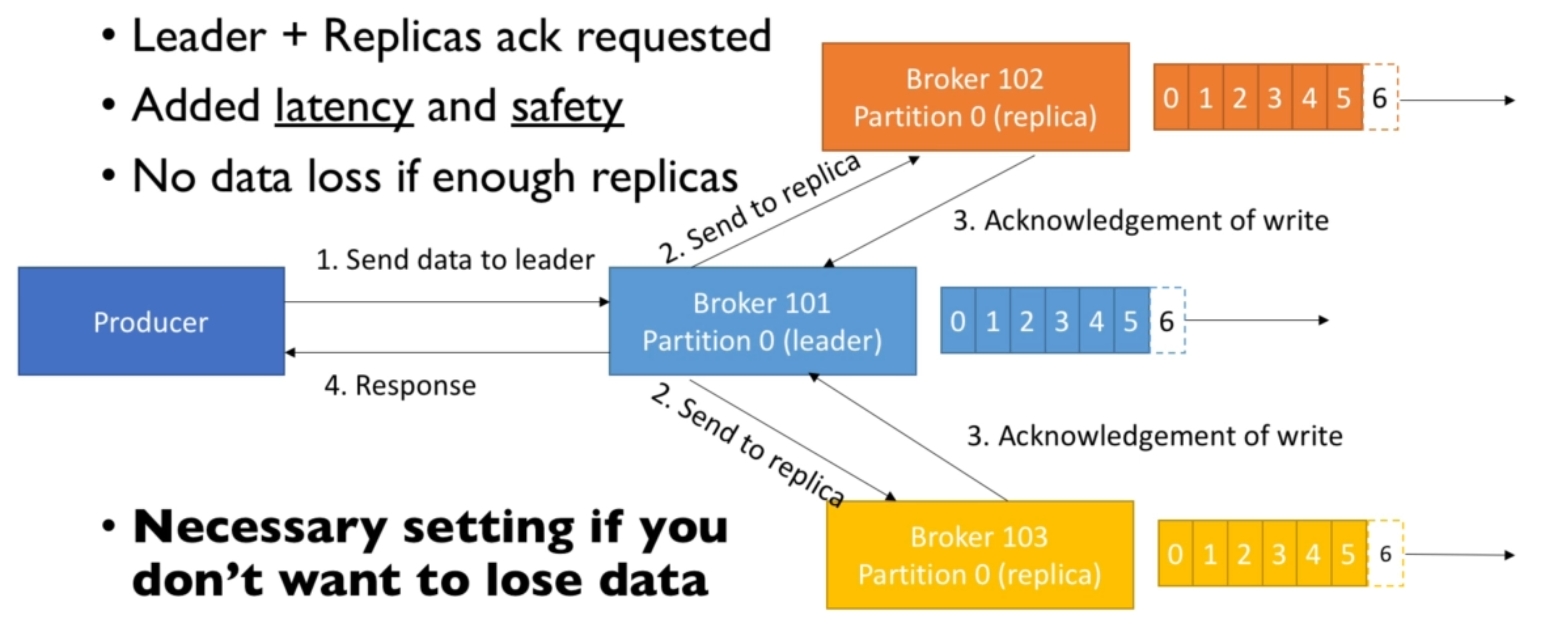
- Producer can choose to receive acknowledgmenet of data writes:
- acks=0: Producer won’t wait for ack (possible data loss)
- acks=1: Producer waits for leader ack (limited data loss) <– selected by default
- acks=all: Leader + replicas acks (no data loss)
Here is the case where acks = all
Producers: Message keys
- Producers can choose to send a key with the message (string, number, etc)
- If key=null, then data is sent round robin
- if key is sent, then all messages with that key will always go to the same partition
- A key is basically sent if you need message ordering for a specific field
- We don’t choose which key goes to which partition, but we know that same key messages endup in a same partition
Consumers
- Consumers read data from a topic (identified by name)
- Consumers know which broker to read from
- In case of broker failures, consumers know how to recover
- Data is read in order within each paritions
- If there are too many consumers than paritions then some consumers will be inactive
Consumer Offsets
- Kafka stores the offsets at which a consumer group has been reading
- The offset commited live in a Kafka topic named __consumer_offsets
- When consumer in a group has processed data received from Kafka, it should be commiting the offsets
- If a consumer dies, it will be able to read back from where it left off. That is possible because consumer commited its offset to a kafka topic
Delivery semantics for Consumers
There are three delivery semantics about when the consumer commits its offset:
- At most once
- offsets are commited as soon as the message is received
- if the processing goes wrong, the message will be lost (it won’t read again, because consumer alerady sent commit command and kafka moved the offset)
- At least once
- offsets are commited after the message is processed
- if the processing goes wrong, the message will be read again
- But the application developer must be cautios about this case, because same message may get processed multiple times
- Exactly once
- Can be achieved for Kafka to Kafka workflows using Kafka Streams API
- For Kafka to External system workflows, idempotent consumer must be used
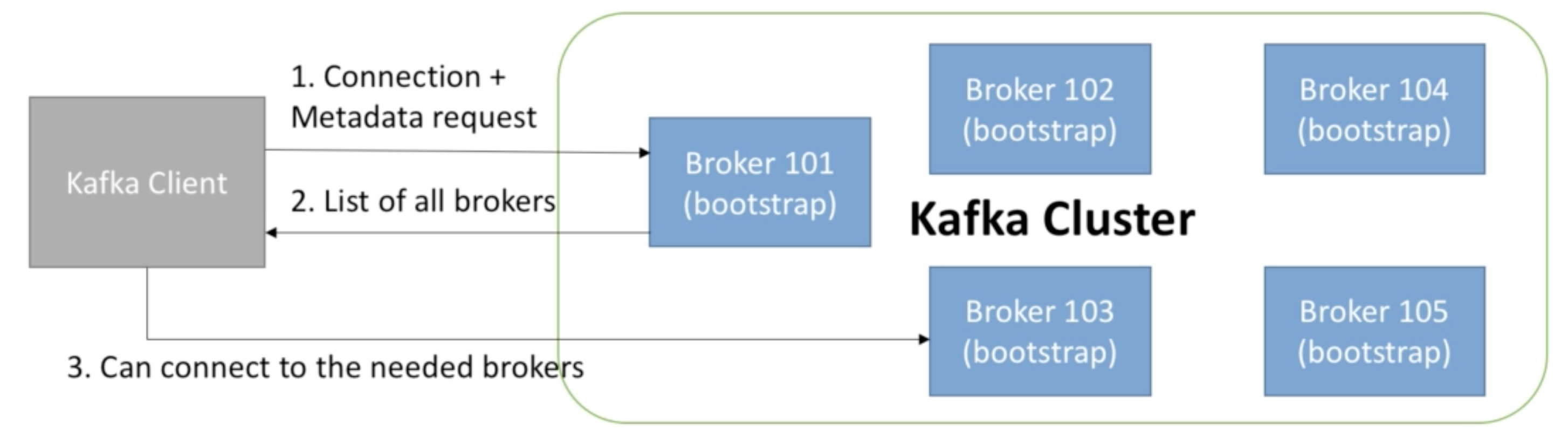
Kafka Broke Discovery
- Every Kafka broker is also called a “bootstrap server”
- That means that you only need to connect to one broker, and you will be connected to the entire cluster
- Each broker knows about all brokers, topics and partitions (metadata)