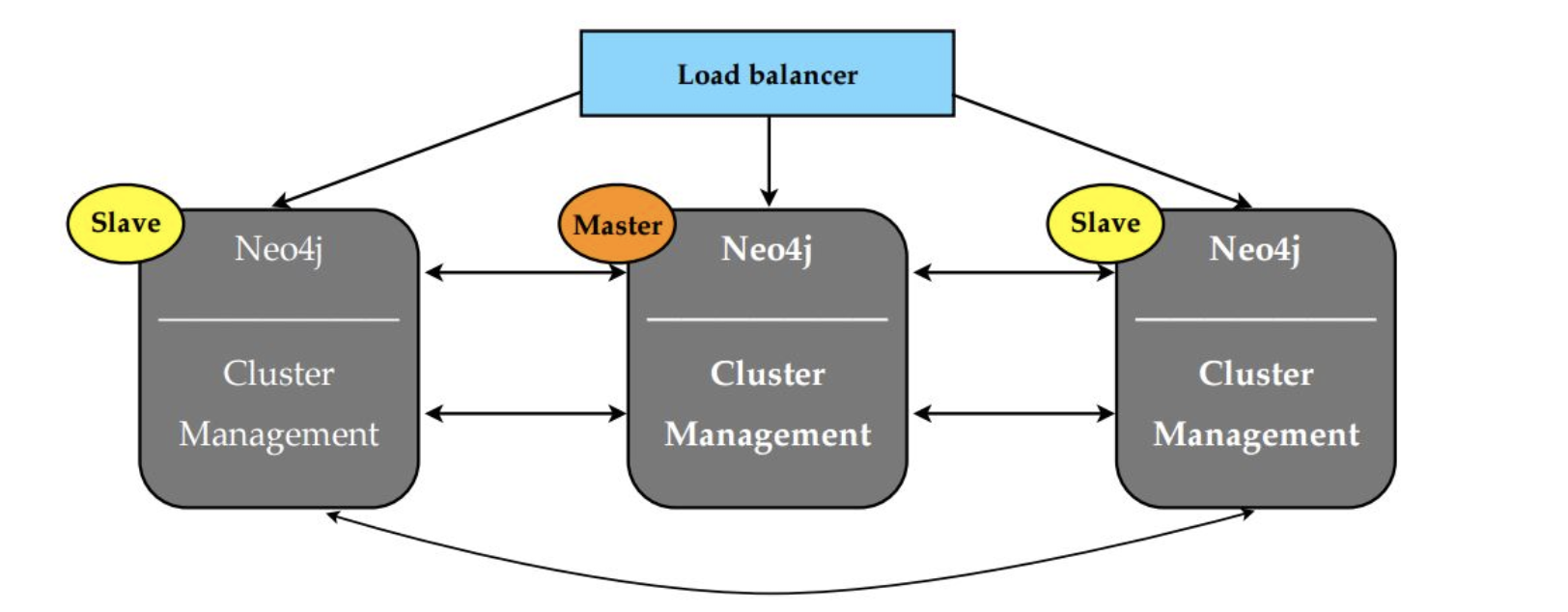
- Replication: Neo4j does allow writing through slaves, even then that’s being written to syncs with the master before returning to the client (writing through slaves works slower then writing directly to the master)
- Buffer writes using queues: this technique can be used in a high write load scenarios, in order to reduce contention. It enables to pause write operations without refusing client requests during maintenance periods.
- Global Clusters: Latency introduced by the physical separation of the regions can sometimes disrupt the coordination protocol. It is better to restrict master reelection by create slave-only databases
- Neo4j cluster, the full graph is replicated to each instance in the cluster
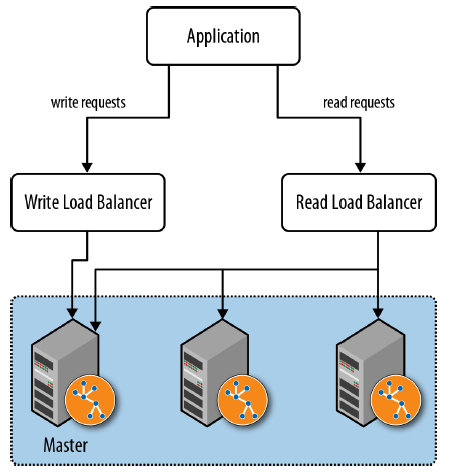
Load Balancing
- Separate read traffic from write traffic. Writing traffic is forwarded to master while balancing the read traffic across the entire cluster
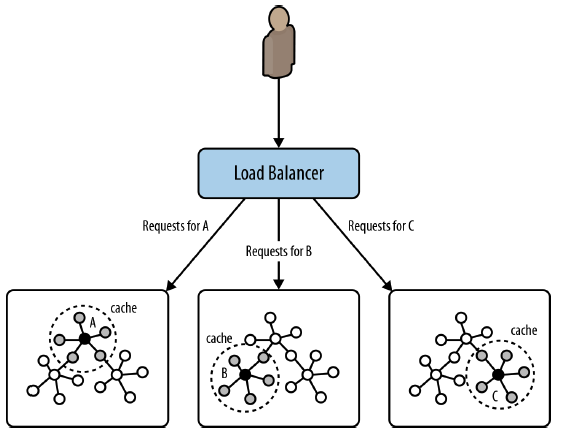
- Cache sharding. This technique is routing each request to a database instance in a HA cluster where the portion of the graph necessary to satisfy query is likely already in main memory
- Read your own writes
Performance Optimization Options
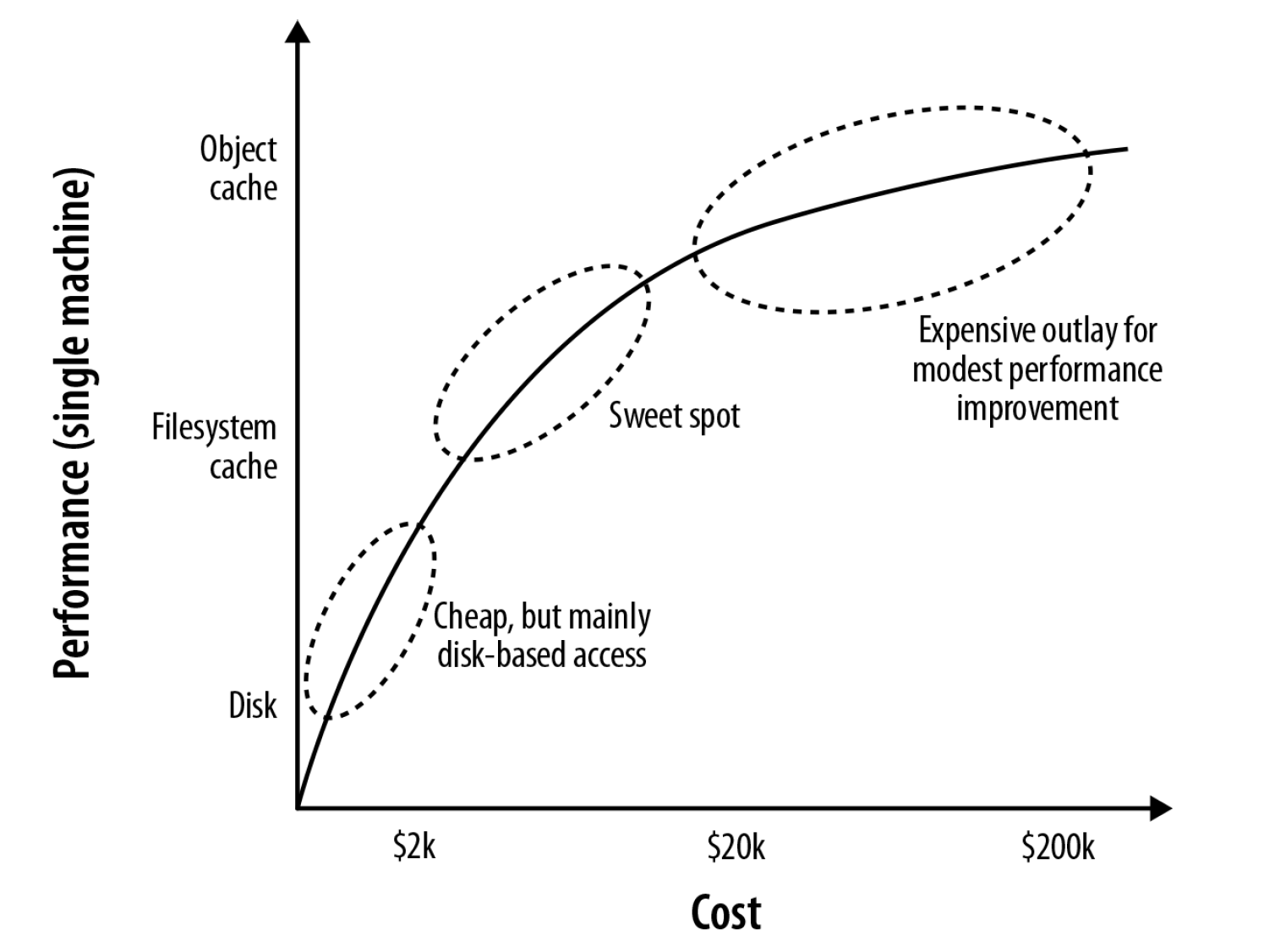
- Increase JVM heap size
- Increase the percentage of the store mapped into the page caches
- Invest in faster disks: SSDs or enterprise flash hardware
Redundancy
- Business-critical applications will likely require redundancy of at least two; that is, even after two machines have failed, the application continues serving requests
- Graph database whose cluster management protocol requires a majority of members to be available to work properly, redundancy of one can be achieved with three or four instances, and redundancy of two with five instances.
CAUTION!: Four is no better than three in this respect, because if two instances from a four-instance cluster become unavailable, the remaining coordinators will no longer be able to achieve majority.
Load
number of concurrent requests = (1000 / average request time (in ms)) * number of cores per machine * number of machines
- Average request time: period from when a server receives a request, to when it sends a response
- Number of concurrent requests: recent production statistics with future estimated number of concurrent requests