In this blog I will try to explain quickly what is a graphdb and how to eat it. First lets answer the question what is a Graph? A graph is a collection of vertices and edges (Say it little simpler graph is a set of nodes and the relationships that connect them)
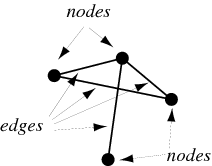
Accordingly graphDB is the database that is build based on the graph. When we talk about GraphDB it is important to undertand it has two main components. Underlying storage and Processing Engine:
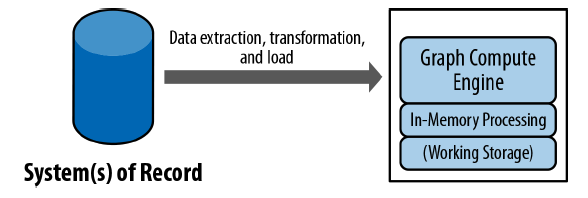
- Underlying Storage is the part which is responsible for storing the data on actual hard disk. There are two kinds of underlying storages possible:
- Native Graph Storage
- Non-Native Storage (Serialize the graph into traditional database):
- Relational database
- Object-oriented database
- General-purpose data stores
- Processing Engine, referes to how a graph database processes database operations. Any database that from the user’s perspective behaves like a graph database qualifies as a graph database. Means that, user must be able to perform CRUD operations on underlying storage. Since underlying storage can be native and non-native, processing engine also differs accordingly:
- Index-free adjacency, is a native way of processing by ensuring that each node is stored directly its adjacent nodes and relationships
- Non-native graph processing engines are implemented based on tradtional database, and uses a lot of indexes in order to complete a read or write transactions. As we know when we applying many indexes on single table the write operation significantly slowing down.
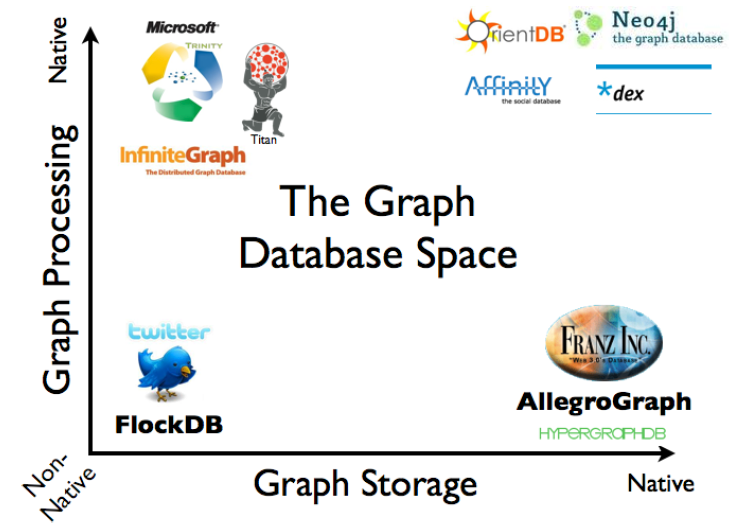
GraphDB products classification by their Storage and Processing engines
Relational Databases Lack Relationships
Ironically relational databases deal poorly with relationships. Relationships in RDBMS exists only at modeling time, but when it comes to the real-world it is a bunch of lookup commands. Sometimes when developer forgets to put a right index and check the query for optimization we can reach a brute force lookups. Relational model becomes burdened with large join tables The rise in connectedness translates in the relational world into increased joins, which impede performance and make it difficult for us to evolve an existing databases in a response to changing business needs.
Fo example, lets consider relational schema for storing customer orders in a customer-centric, transactional application:
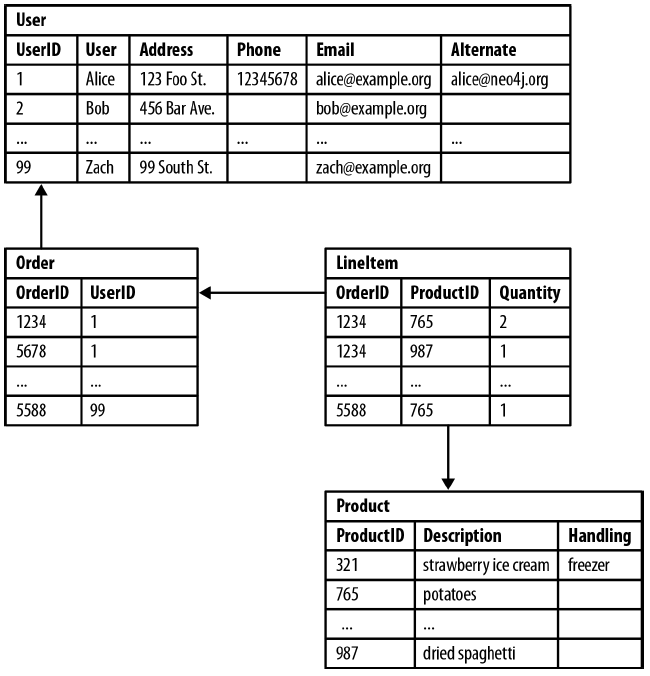
- Join tables add accidental complexity, by mixing business data with foreign key metadata
- Foreign key constraints add additional development and maintenance overhead just to make the database
- Several expensive joins are needed just to discover what a customer bought
- Query “Which customers bought this product?” can become even more expensive.
- The query such as “Which customer buying this product also bought that product?” quickly become prohibitively expensive as the degree of recursion increases
Lets consider another example with highly connected domain (modelling friends-of-friends:
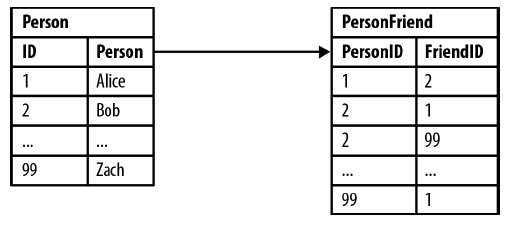
Based on above simple schema try to perform some queries:
Who are Bob’s friends?
SELECT p1.Person
FROM Person p1 JOIN PersonFriend
ON PersonFriend.FriendID = p1.ID
JOIN Person p2
ON PersonFriend.PersonID = p2.ID
WHERE p2.Person = ‘Bob’
Who is friends with Bob?
SELECT p1.Person
FROM Person p1 JOIN PersonFriend
ON PersonFriend.PersonID = p1.ID
JOIN Person p2
ON PersonFriend.FriendID = p2.ID
WHERE p2.Person = ‘Bob’
Who are friends of my friends?
SELECT p1.Person AS PERSON, p2.Person AS FRIEND_OF_FRIEND
FROM PersonFriend pf1 JOIN Person p1
ON pf1.PersonID = p1.ID
JOIN PersonFriend pf2
ON pf2.PersonID = pf1.FriendID
JOIN Person p2
ON pf2.FriendID = p2.ID
WHERE p1.Person = ‘Alice’ AND pf2.FriendID <> p1.ID
First two queries are easily can be used, even though the second query would take a longer if we don’t do indexing of necessary columns. But when we come to the third query, it would take longer and longer as we increase the depth of the friendships line.
Now lets see the database designed using GraphDB approach.
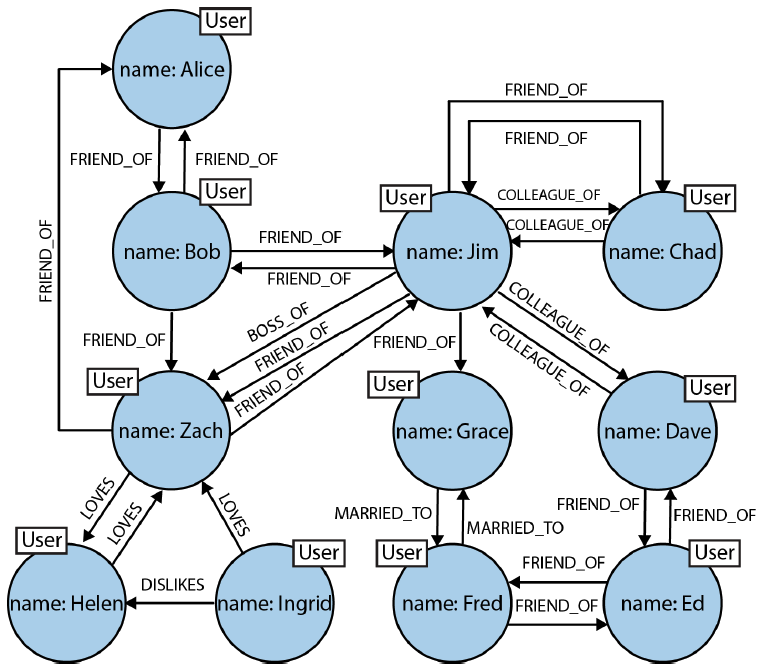
Of course it is not described in a schema way, but we just create a nodes with user names and put the relationships where it is needed.
In order to convince ourselves to select graphDB for the domain problem where highly connectedness is needed, we can refer to past experiments of Partner and Vukotic.
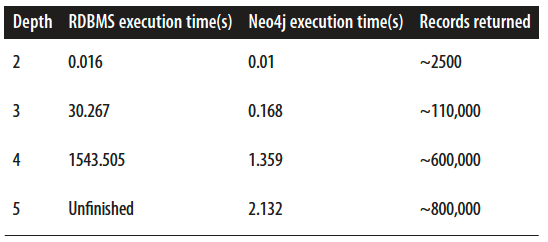
Partner and Vukotic’s experiment seeks to find friends-of-friends in a social network, to a maximum depth of five. Social network containing 1,000,000 people each with approximately 50 friends. At depth two (Friends-of-Friends) relational database and graph database perform well enough, although Neo4j query runs in two-thirds the time of relational database. Starting from depth three RDBMs solution is unacceptable for the real-time service (it takes 30 seconds)
Another quick example for user’s order history can be modelled as follows:
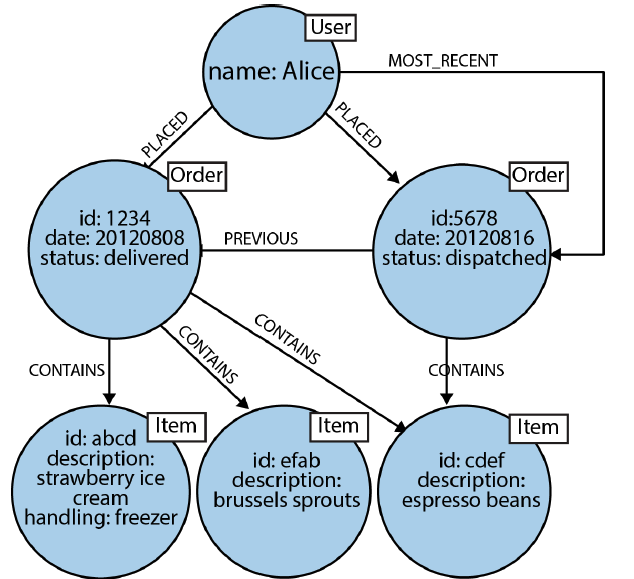
As it can be seen from above figure, we have a freedom while designing our database properties and relationships. We can use various relational edges coming out from vertexes with different values. For example We can see that Alice placed two orders and by using MOST_RECENT edge we can see which one of the are the most recent order. That gives us freedom of designing databases with multiple domains (Cross-Domain models)
Here is another sophisticated Cross-Domain model example:
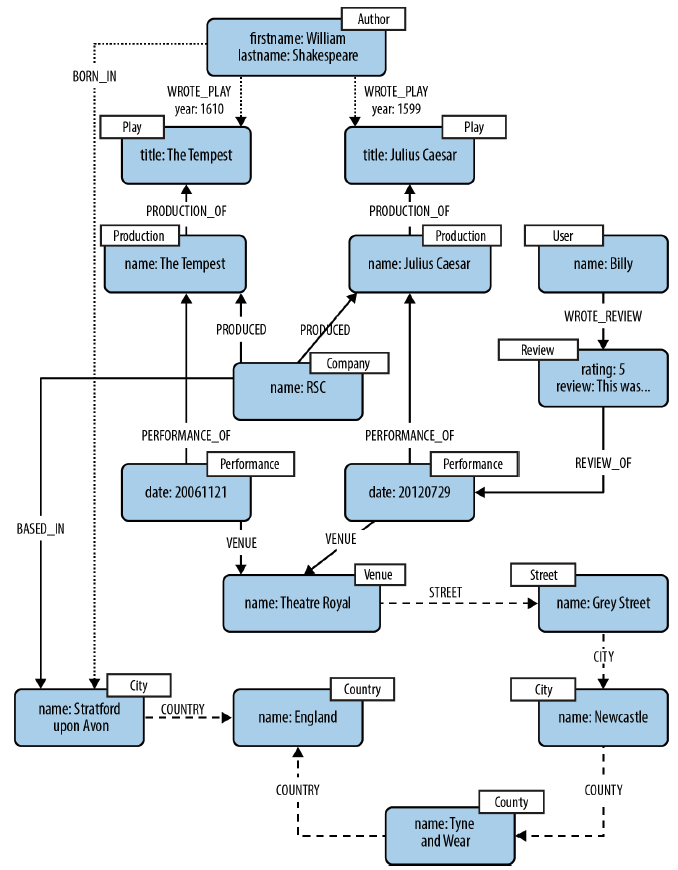
- Business insight often depends on understanding the hidden network effects at play in a complex value chain
- Using property graph we can model a value chain as a graph of graphs in which specific relationships connect and distinguish constituent subdomains
- Adding new domain relations into existing domain graph does not destroy existing relations
For GraphDB modeling pitfalls follow to here