Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is a serverless infrastructure that allows us to run SQL on S3 files. Athena helps to analyze unstructure, semi-structured and structured data stored in Amazon S3 (such as CSV, JSON, columnar data formats, Apache Parquet, Apache ORC). Detail references can be read from official aws web-page
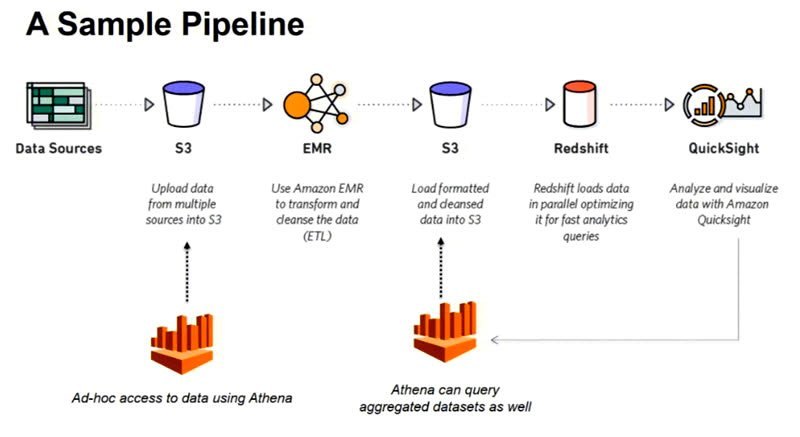
- There is no concept of loading data into Athena, when you are not using Athena you are not paying for it, You just pay for data that is sitting on S3
- Use ANSI SQL, support for complex joins, nested queries & window functions, support for complex data types (arrays, structs), support for partitioning of data by any key
- Uses presto for SQL Queries
- Uses Hive for DDL functionality
- Schema on Read (like Hive)
- less data is scanned less we pay (compressing and columnar format approach is good for optimization)
Amazon Athena is Fast
- Tuned for performance
- Automatically parallelizes queries
- Results are streamed to console
- Results also stored in S3
- Improve Query performance
- Compress your data
- Use columnar formats
Cost Effective
- Pay per query
- $5 per TB scanned from S3
- DDL Queries and failed queries are free
- Save by using compression, columnar formats, partitions
Quick Run
We have to create Athena database and table which is going to do crawling over Amazon S3 bucket rather than a file. Location path of S3 bucket must be given by considering a partition. It means some part of the path can become a partition and be served as a column.
if the table that is partitioned by Year, then Athena expects to find the data at S3 paths similar to the following
s3://mybucket/athena/inputdata/year=2016/data.csv
s3://mybucket/athena/inputdata/year=2015/data.csv
s3://mybucket/athena/inputdata/year=2014/data.csv
If the data is located at the S3 paths that Athena expects, then repair the table by running a command similar to the following:
CREATE EXTERNAL TABLE Employee (
Id INT,
Name STRING,
Address STRING
) PARTITIONED BY (year INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION 's3://mybucket/athena/inputdata/';
After the table is created, load the partition information by using a command similar to the following:
MSCK REPAIR TABLE Employee;
Details regarding to partitioning can be found from here
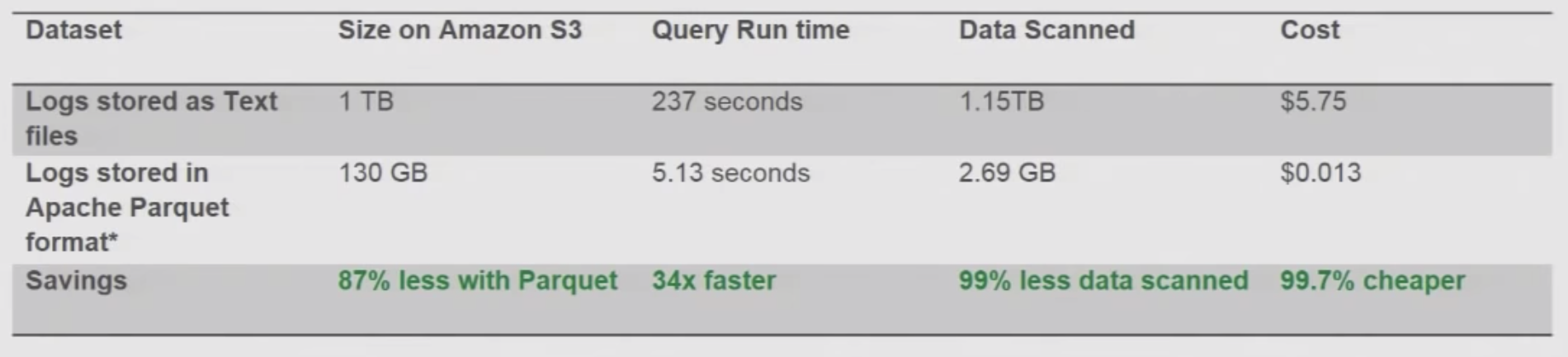
Compression is Useful
In order to save time and money, it is better to change the format of the data from json to Apache Parquet or Apache ORC. Here is we will shortly describe why it is useful. First lets intorduce little about those formats
Parquet
- Columnar format
- Schema segregated into footer
- Column major format (min, max, count values are precalculated)
- All data is pushed to the leaf
- Integrated compression and indexes
- Support for predicate pushdown
ORC
- Apache Top level project
- Schema segregated into footer
- Column major format
- Integrated compression, indexes and stats
- Support for Predicate Pushdown
Converting to ORC and Parquet
- It is possible to use Hive CTAS to convert data
CREATE TABLE new_key_value_store
STORED AS PARQUET
AS
SELECT col_1, col_2, col_3 FROM noncolumnartable
SORT BY new_key, key_value_pair;
- Also usage of Spark possible to convert the file into PARQUET / ORC
- 20 lines of Pyspark code, running on EMR
- Converts 1TB of text data into 130 GB of Parquet with snappy conversion
- Total cost $5
Comparison Result for Compression
- Pay by the amount of data scanned per query
- Ways to save costs
- Compress
- Convert to Columnar format
- Use Partitioning
- Free: DDL Queries, Failed Queries
SELECT elb_name, uptime, downtime, cast(downtime as DOUBLE)/cast(uptime as DOUBLE) uptime_downtime_ration
FROM
(SELECT elb_name, sum(case elb_response_code
WHEN '200' THEN
1
ELSE 0 end) AS uptime, sum(case elb_response_code
WHEN '404' THEN
1
ELSE 0 end) AS downtime
FROM elb_logs_raw_native
GROUP BY elb_name)
Naming Issue with Athena (BE CAREFUL !!)
I have spent an hour and couldn’t create a athena table from S3. The table I have created stayed empty, and when I run msck repair table <tableName> it gave me an error
Your query has the following error(s):
FAILED: ParseException line 1:7 missing EOF at '-' near 'database1'
This query ran against the "database1-dev" database, unless qualified by the query. Please post the error message on our forum or contact customer support with Query Id: a39c130a-5935-4569-8834-663001e2919f.
after doing some googling, I have found that athena is quite sensitive about naming of databases and tables. Thats because when I have created new database with name database1dev (instead of database1-dev) it has worked without any problem.